软件级 是相对于程序级 的概念,软件级应用往往包含多目录多文件的大量源代码 ,有复杂的第三方库依赖关系 。
软件级应用的编译用时往往较长,并且过程相对繁琐。
我们这里介绍使用 MinGW 系列工具和 CMake 编译 cpp
软件级应用的过程和知识。
各种文件
CMakeLists.txt
CMakeLists.txt 一般用于跨平台的大型软件级项目,用于指示
CMake 生成平台对应的编译选项 ,也就是
Makefile 文件。
Makefile
Makefile 文件指定 make 工具编译生成
include/,lib/,bin/
等成品的方式,我安装的是 MinGW套件,命令是
mingw32-make。
.dll/.so
这两个是动态链接文件,.dll 是 Windows 下的,.so 是 Linux 下的。
MinGW 默认是动态链接的,编译生成的 .exe 如果找不到 .dll
就运行不了。
.dll 或者 .so
默认只会在系统路径和工作目录 两个地方去找
.o
.o
是可重定向目标文件 ,是汇编过程生成的源文件机器语言代码。
.a
.a
是静态链接归档文件 ,如果采用静态链接的方式编译,就需要在编译时加上这个。
它等价于把若干个 .o 打包在了一起。
C++ 编译速通
编译步骤:
预处理:把 #include 的东西全部粘贴到对应的位置,由
.cc,.cpp 生成
.i,.ii 预处理文件 。
编译:编译器用 C/CPP 代码生成汇编代码,由
.i,.ii 生成 .s
汇编文件 。
汇编:由汇编器将汇编代码编程二进制代码,由 .s 生成
.o 目标文件 。
链接:由链接器把汇编的机器代码 .o,打包的静态链接库
.a,动态链接库 .
静态链接和动态链接的区别:
静态链接在编译时便将中的实现 放入了 .exe
文件,在运行 .exe 时就将代码放入内存 。
动态链接在运行时才去 .dll
中查找实现 ,并在调用对应函数时将这部分代码放入内存 。
无论是静态链接还是动态链接,编译时都需要指定链接库 。静态和动态的区别在于将对应代码加入内存的时间 。
实现 通常写在 .cpp
文件中,定义 通常写在 .h 文件中,#include
时一般只会 #include .h
文件,所以如果编译时不指定链接库,链接步骤 就会报
Undefined Refference 错误。
GNU-make 工具的使用
类 UNIX 环境下它叫 make,但是我们用的
MinGW,反正我这里叫 mingw32-make,路径是
path/to/mingw64/bin/mingw32-make.exe
,使用时记得加环境变量。
make 和 Makefile 结合,执行一些特定的命令,完成项目的编译,避免手敲
gcc 命令。
命令格式:
1 [mingw32-]make [<目标>] <可选参数...>
常用可选参数:
-n:不执行,只打印要执行的命令。-f:指定 Makefile 的路径,默认情况下 Makefile
的(相对)路径为 Makefile 或 makefile。-j[<num>]:多线程编译,例如 -j4
表示四线程编译。
目标是指 make
要执行的具体任务,如果没有指定目标,那么会执行第一个非伪目标 。
Makefile 解读
一般情况下需要我们写 makefile 的机会不是很多,会读和改就可以了。
变量操作
<VAR_NAME> ?= <EXPR>
条件赋值,如果还没定义 这个变量才赋值,规则同递归赋值 。<VAR_NAME> = <EXPR
递归赋值计算,每次使用时重新计算 。<VAR_NAME> := <EXPR
立即赋值计算 ,只计算一次。$(<VAR_NAME>):引用变量。
目标
目标的格式是 <target>:[<dependencies>]。
当 make
执行某个目标时,会对依赖项进行检查,如果依赖项对应的文件不存在,则会将先执行依赖的名字对应的目标 。
例如:
1 2 3 4 5 foo: foo.o gcc -o foo foo.o foo.o: foo.c gcc -c foo.o foo.c echo "compiled foo.o"
执行 make 时,过程如下:
没有指定目标,会找到第一个目标 foo 执行。
查找其依赖 foo.o,发现不存在,于是查找目标
foo.o。
找到 foo.o 其依赖 foo.c
作为一个文件存在,于是执行 gcc -c foo.o foo.c 编译生成
foo.o。
返回 2. 中步骤,依赖 foo.o 已经存在,执行
gcc -o foo foo.o 生成 foo[.exe]。
目标规则
有时候可能有很多文件,某些文件的生成方式,例如
.o,是一致的,这时可以利用目标规则 来定义目标。
查找目标时,规则优先级为:越具体越优先 。
目标规则大致分为三种:
显式目标规则
见上。
显示模式规则
显式模式规则使用通配符 %
来匹配任意字符 ,包括目录分隔符。其余同上。
下面的 $< 和 $@
是自动变量 ,下面的部分有详细解释。
1 2 3 %.o: %.c echo "Using generic rule" gcc -c $< -o $@
隐式模式规则
隐式规则模式用于指定生成对应后缀名的文件 ,常见的有:
.c.o: 从 .c 文件生成 .o
文件。.cpp.o: 从 .cpp 文件生成 .o
文件。.cpp.exe: 从 .cpp 文件申城
.exe 文件。
伪目标
一般情况下,目标会作为一个文件,通过判断文件是否已经生成来判断是否已经完成该目标。
但是,如果修改了 .cpp 源代码,但是 makefile 中有生成 .o 的过程,.o
还被保留了,那么再次 make 的时候检测到 .o 已经存在,只会用已经存在的 .o
重新链接生成一次可执行文件,没有达到重新编译的效果。所以,往往需要定义一个"清理操作",来清理相关的文件以便重新完整编译。
"清理操作" 显然不生成文件,为了完成这个操作,引入了 "伪目标"
概念,伪目标在文件开头用 .PHONY 声明,例如:
1 2 3 4 5 6 7 .PHONY : cleanall: clean foo.o g++ -o foo foo.o foo.o: foo.c g+++ -c foo.o foo.c clean: rm *.o
这样便可以在每次执行 make 时清理缓存的 .o
文件达到重新编译的效果。
提醒:
伪目标表示一个过程,作为依赖时一定会被执行 ,如果执行返回代码为
0 才判定为完成,否则判定为没有完成,可能报错。
严格来说 all 也应该被定义为伪目标,实际上由于不会生成 all
文件,也就无所谓,clean 有时候不会被声明为伪目标。
make
不指定目标时,如果存在非伪目标,那么执行第一个非伪目标,否则仍然执行第一个目标 。
自动变量
自动变量是执行规则时根据上下文动态生成的变量 。
常用自动变量表如下:
$@
$<
$^
CMake 系列工具使用
不同平台使用的编译工具不一定相同,有时候根据实际情况,也可能会选择性编译整个项目的一部分。如果只提供
Makefile 可能不方便。这个时候可以利用 CMake 系列工具和 CMakeLists.txt
来根据具体需求生成特定的 Makefile 。
CMake 工具可以在这里 下载。
检查一个项目根目录是否包含 CMakeLists.txt
以便确认它是否支持使用 CMake 系列工具。
CMake-GUI 有个 Bug,详见 。
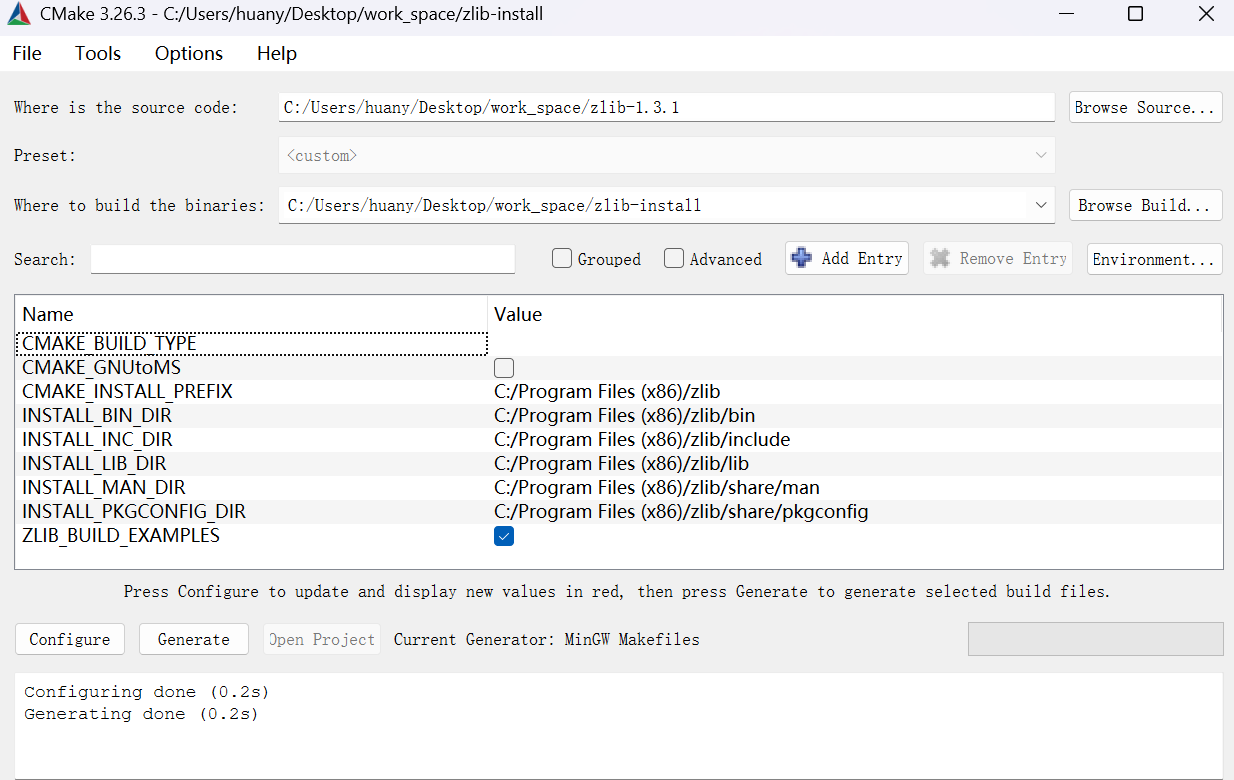
下面是 CMake 的 UI:
image-20250309195350524
配置源代码和构建路径
两个位置需要填写源代码目录(包含
CMakeLists.txt)和构建目录(自己创建一个)。
image-20250309195243176
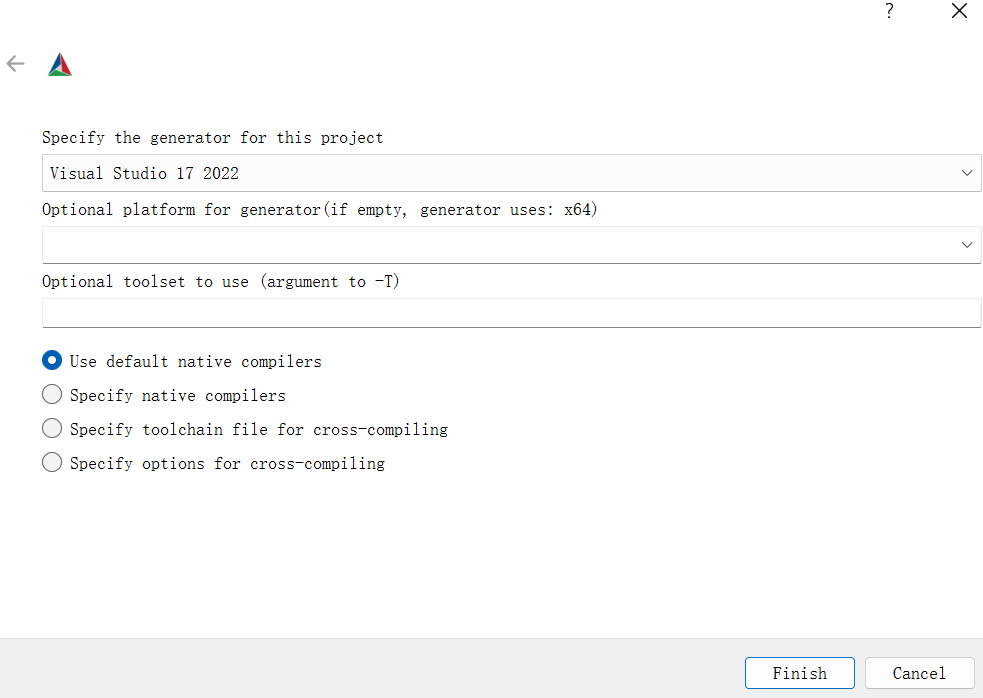
点击 Configure,会先让你选编译器之类的:
image-20250309200631860
我们用 MinGW,翻一下找到选上就行,点 Finish
会自动读取所需配置项,读完之后你可以用 UI 界面方便的对它们进行改动。
Configure 过程也会读取平台信息等,大型项目 Configure 用时会很长。
如果改动了配置,需要再点一次 Configure 。
由于 CMake 缓存相关的问题,如果第一次 Configure 爆红,也需要再点
Configure 一次解决问题。
Generate
完成 Configure 后,点 Generate,会在 build 目录生成 Makefile
和所需要的文件,在 build 目录执行 make 命令即可。
直接编译
gcc
命令格式:
1 gcc <功能参数> [主参数...] [包含目录参数...] [链接目录参数...] [链接参数...] [编译选项...]
功能参数
-o:完成链接停止。-c:完成汇编停止。-s:完成编译停止。-E:完成预处理停止。 主参数
主参数用于指定执行这次操作所需的各种文件的位置,包括 .cpp
文件、.a 文件、.o
文件 等,如果这里没有显式指定,可以通过下面的参数补充指定 。
包含目录
包含文件不能在主参数部分指定,必须位于包含文件搜索目录下。
#include
除了在工作目录和系统路径 搜索之外,还可以使用多个
-I path\to\include
来指定包含文件搜索目录 。
链接目录
使用 -L
参数指定链接搜索目录 ,需要和链接参数配合使用 。
链接参数
使用 -l 参数,语法规则为
-l[链接名](注意没有空格),优先链接到链接目录下动态链接文件
/path/lib[连接名].dll
文件。如果不存在动态链接,则会链接到静态链接文件
/path/lib[链接名].a 文件。
链接库可以在主参数中直接指定 ,写它的路径即可。
例如 -L ./lib/ -lzlib 等价于主参数中添加
./lib/libzlib.dll 或者
./lib/libzlib.a。
编译选项
--static:强制使用静态链接。-O2:开启 O2 优化。-g:生成调试符号表启用 gdb 调试功能。-Wl,-rpath,<path/to/dll>:指定运行时链接搜索目录 ,运行时最优先到
path/to/dll 去搜索 .dll
文件,一般使用相对路径
示例(我使用了 [] 和 () 来划分部分,实际使用时需要去掉):
1 [g++](命令) [-o main.exe](功能参数) [cli/main.cpp resource.o](主参数) [-I "C:\Users\huany\Desktop\work_space\ziptools-install\minizip-install\include" -I "C:\Users\huany\Desktop\work_space\ziptools-install\zlib-install\include" ](包含目录) [-L "C:\Users\huany\Desktop\work_space\ziptools-install\minizip-install\lib\" -L " C:\Users\huany\Desktop\work_space\ziptools-install\zlib-install\lib\"](链接目录) [-lminizip -lzlibstatic](链接参数) [-fpermissive --static](编译选项)
ar
使用 ar 工具将多个 .o 文件打包成一个
.a 静态库文件。例如:
1 ar cr libmylib.a file1.o file2.o
这里,libmylib.a
是生成的静态库文件名,file1.o 和 file2.o
是输入的目标文件。
动态链接
我觉得自己造的轮子就没必要搞动态链接了,全静态吧。想起来我再补上。
软件的发布
发布 .cpp 编译生成的 .exe
软件时,需要考虑到用户的机子上没有运行环境的事实,一般采用两种方式:
全静态链接 --static。同时发布所需的 .dll 文件 ,放在 .exe
同级目录下或者使用 -rpath 编译参数。折中 。
练习——Windows 编译 OpenCV
OpenCV
是使用最为广泛的计算机视觉库,编译文档十分完善,也有数量可观的资料可供查询。但
OpenCV 体型巨大,编译用时较长。
OpenCV源码
编译完成后应该得到以下文件:
包含目录 include/
静态链接库 lib/
动态链接和其它二进制文件库 bin/
练习——Windows 系统编译
minizip
minizip 是 zlib 库的一个子库,能够支持压缩和解压。minizip
目前已经放弃维护,相比成熟的
OpenCV,可能需要修改一些编译命令才能完成编译。
你需要完成 minizip 和 zlib 的编译,得到以下文件:
zlib 的包含目录 include/ 和静态链接库
lib/。
minizip 的包含目录 include/ 和静态链接库
lib/。
提醒:
注意,官方的 makefile
中可能没有生成目录的步骤,你可能需要手动创建目录或者更改
makefile。
minizip 的 makefile 无法针对 windows
使用,请自行排查其错误并进行修改后完成编译,或者使用 g++
手动编译生成有关文件。
你可以用 CMake 完成 zlib 的编译,也可以阅读下面文档手动编译:
To compile all files and run the test program, follow the
instructions given at the top of Makefile.in. In short "./configure;
make test", and if that goes well, "make install" should work for most
flavors of Unix. For Windows, use one of the special makefiles in win32/
or contrib/vstudio/ . For VMS, use make_vms.com.
minizip 源代码位于
zlib/contrib/minizip/,请自行解读代码结构并进行操作。注意其依赖的
zlib 相关的配置。
大练习——编译 NcatBot 发行包
背景简介
ncatbot 旨在让用户无门槛使用,开发者只关注业务代码,提供了一个
windows 平台下的 .exe 安装部署工具。
该工具只包括一个 main.exe
主程序 ,能够无下载过程 的配置基础 Python
环境,并安装 ncatbot 本体,调用 ncatbot-cli 完成后续交互。
相应的代码 main.cpp,Python 环境压缩包
package.zip 都已经给出,请编译出可执行文件
main.exe。
有关资源
指示
main.cpp
开头部分含有编译命令,参考这一部分编译命令,你需要完成如下工作:
完成 zlib,minizip 的编译。
完成 package.zip 的编译。
正确书写设置 zlib,minizip 的路径和编译命令。
编译 main.cpp 并链接其它上述资源。
在 NcatBot-Release
中含有编译好的
zlib,minizip,package,如果你实在无法完成这些部分,可以下载使用并完成接下来的部分。
附录
命令格式书写语法
这是一种约定俗称的记号,而不是一个严格规范 ,每位开发者使用的书写方式不一定相同,也不会特意严格按照要求书写,下面给出我的习惯记号。
[EXPR]:表示这一部分是可选的。
[mingw32-]make:可能是 mingw32-make 或者
make。有些人也会写成 (),但一般不会写成
<>。
<VAR>:表示一个变量,需要根据实际情况更改。
有时候你会明显感觉到不用 <>
包起来也表示一个变量,自己灵活处理,例如 path/to/zlib/
可能表示 C:/Program Files(x86)/zlib/。
有时候也会写成 []。
<VAR...>:表示这里的参数个数是动态变化的,每个参数用空格分隔,可以是
0 个。
<编译选项...> 可能表示
-O2 -fpermissive 或者 -O2 --static 或者
--static 或者啥都没有。有时候也会写作 [VAR...] 或者
[<VAR>...]。
更多自动变量
$?
含义 :表示依赖列表中比目标文件更新的依赖项(以空格分隔)。
用途 :常用于条件编译或增量构建,只处理那些真正需要更新的文件。
示例 :
1 2 foo.o: foo.c header.h gcc -c $< -o $@
如果 header.h 被修改,$? 的值是
header.h。
$*
$+
$|
$(@F) 和 $(@D)
$(*F) 和 $(*D)
$(*F)$*
的文件名部分。
$(*D)$*
的目录部分。
示例 :
1 2 3 4 build/foo.o: src/foo.c gcc -c $< -o $@ echo "File: $($(*F))" echo "Directory: $($(*D))"
如果目标是 build/foo.o:
$(*F) 的值是 foo$(*D) 的值是 build