几道题目引发的思考
几道题目引发的思考
- 未完成,咕咕咕中。
NOI2013书法家
这道题,我写了个 DP+枚举 的方法交了上去,第一发喜提 TLE,开 O2 后成功通过,并且速度是不开 O2 的 10 倍,看题解后发现,相比于纯粹的 DP 做法,自己的枚举做法其实很蠢很难想也很难写,于是对 DP 和枚举的关系进行了一些思考。
O2 优化的高达 10 的效率改进因子也着实让我觉得有些不可思议,于是便对 O2 优化在份代码上到底干了什么做了一些探索.
同时,将内联函数改为宏定义后,我的程序也得到了明显的效率改进,便有了宏定义与函数的比较。
下文将从这些角度入手,进一步分析一些底层的程序效率问题。
CF1709F
考场上图方便 #define int long long,用
Codeforces 的 C++14 提交喜提 TLE,改为
C++20(64bit) 后成功通过,于是便有了对 64bit 机子和 32bit
机子,int 与 long long 比较的想法。
浅谈 DP 枚举与一般枚举算法的差异与优劣
DP 枚举也是枚举
回到题目本身,我们考虑处理字母 O 和 I
时,枚举算法的本质。
处理 O
的时候,枚举算法枚举了上下两个行,和一个左端点,通过前缀和算出了类似这样的一个结构的权值
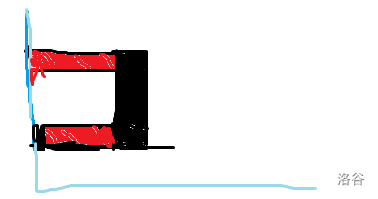
红色部分是负权值。
然后我们又计算了一个这样的结构的后缀最大值。

如果把这两个结构拼在一起,就得到我们想要的答案。
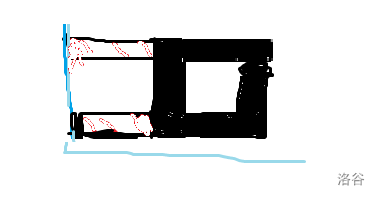
红色部分和黑色部分抵消掉了,得到了想要的答案。
如果用 \(dp\) 来处理,我们就设了 \(dp[i][l][r]\) 考虑到第 \(i\) 行,顶部和底部分别是 \(l,r\) 的最大值,转移相当自然,从没有到一列,再到两格,从两格加上一列计算答案。
其实这种 \(dp\) 和我们的枚举算法没有差异,都是确定了上下以及左右的一个端点,通过记录的辅助状态来完成转移。DP 记录的辅助状态就是答案,而枚举记录的辅助状态是抽象的前缀和。因而后者比前者要更难理解。
DP 比枚举更加自然
从刚刚处理简单的 O
还看不出来差异,我们现在来处理更为复杂的
I,实际上,我们用枚举算法计算 I
的时候,处理了三个辅助状态。
MSPAINT已经满足不了绘图要求了,还是手最靠谱
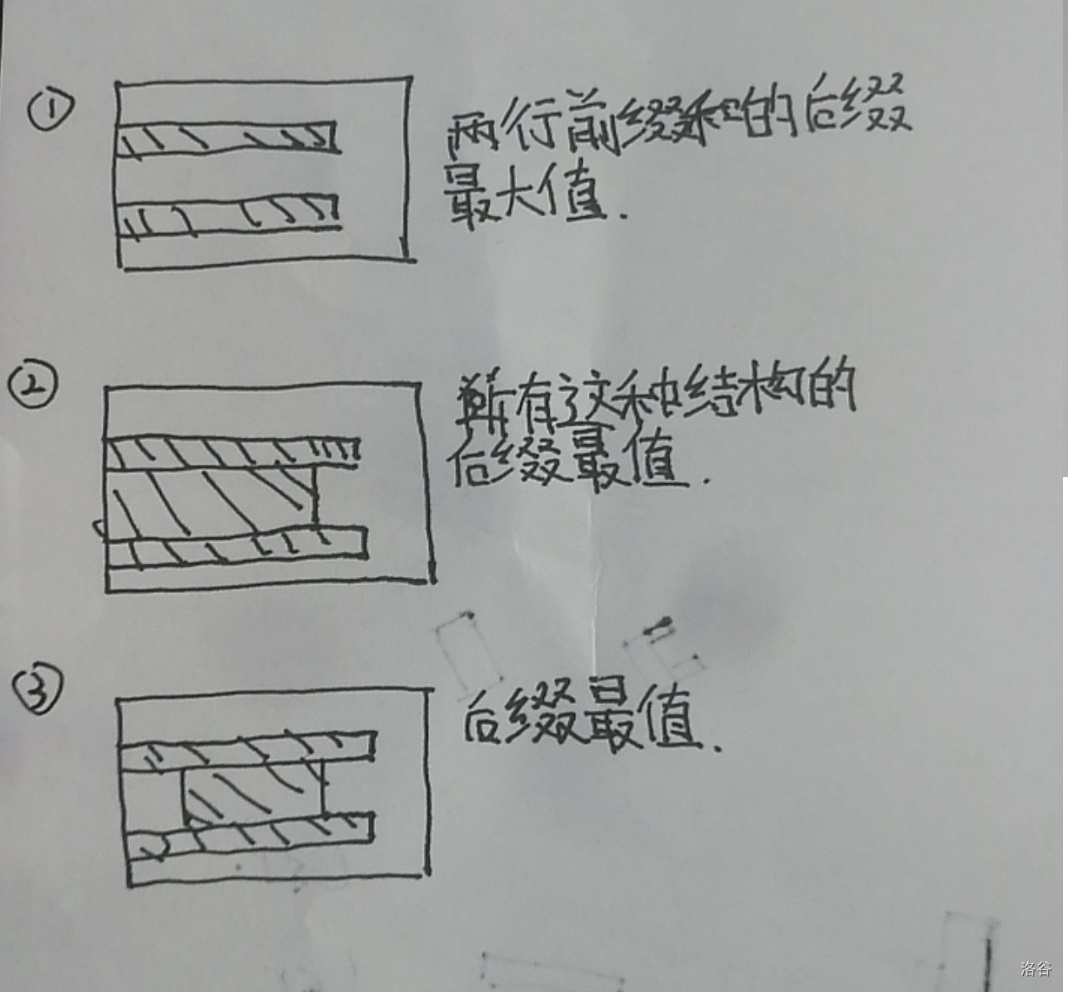
不难发现对 O
来说,确定了左上右下就已经确定了整个图形的结构了,而对于 I
来说,确定了左上右下,还需要额外确定两个参数才能确定权值,这样带来了
\(O(n^2)\) 种方案。
直接枚举,我们思考的量就是 \(3^2\) 级别的,因为我们需要考虑这三种情况相互之间的影响。
而如果考虑 DP。我们就只需要设计三种不同状态,而每种状态保存的辅助数据又是直观的答案,相比于枚举算法的弯弯绕绕计算答案,DP,在计算答案时只需要简单的加和,转移的方式也只有 \(2\) 种,孰优孰劣不言而喻。
在跨域三种状态转移的过程中,其实就已经完成了枚举算法对上图里所有情况的考虑,所以不会和枚举算法有任何本质差异,但是 DP 这种直接记录答案作为辅助数据的方式,无疑更加自然,思考也更加简单。
浅谈 O2 优化在公共子表达式与寻址中的实际作用。
对公共子表达式的优化
提到了一个定义,公共子表达式。一般的,公共子表达式,指的是这种
1 | int a=1,b=2,c=3,d=4; |
其中,c*d 就是公共子表达式。
看一个不同优化下两种代码的汇编

无优化版本。
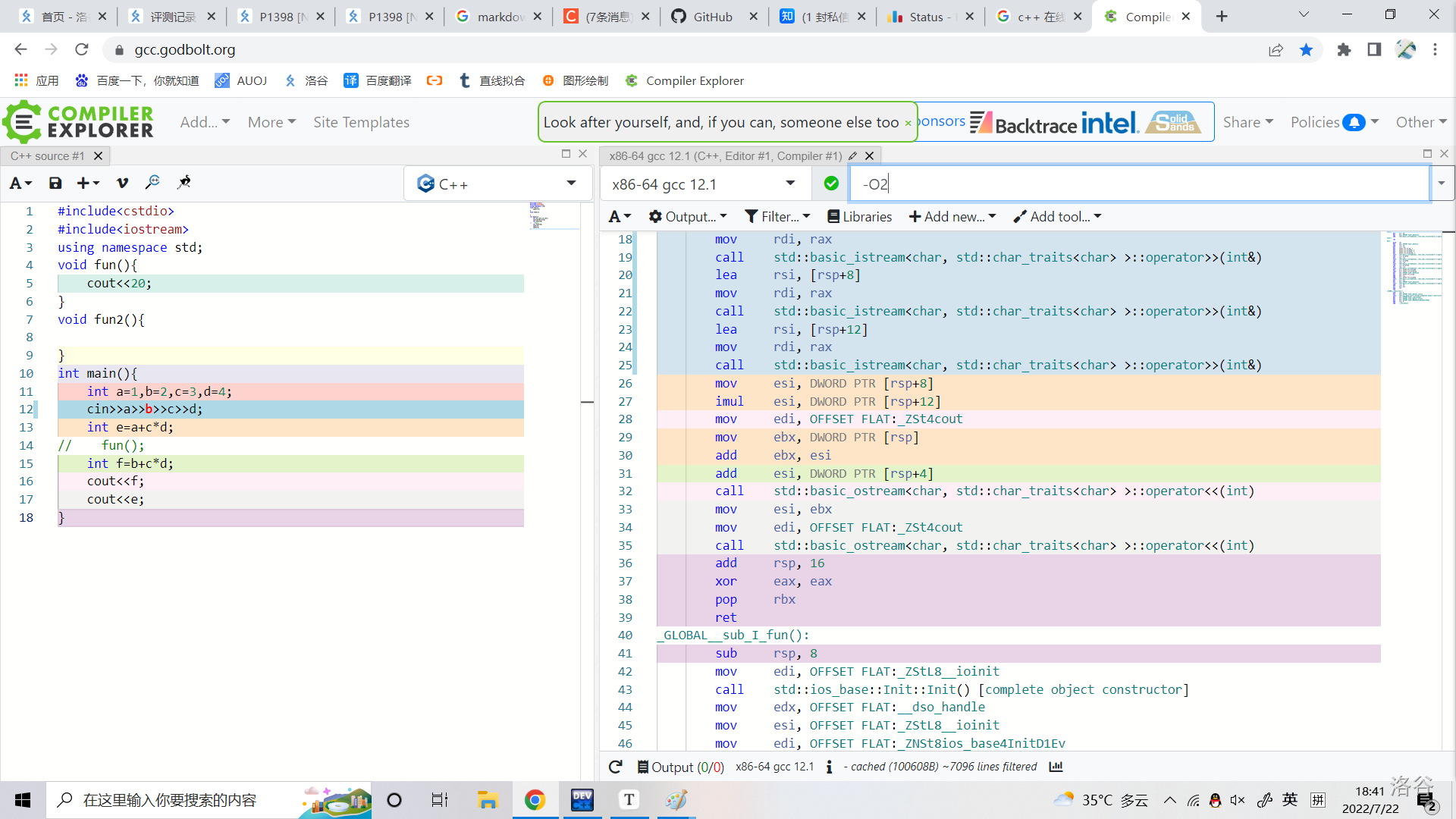
有优化版本。
编译器帮我们把 \(c*d\) 算好了,扔进了寄存器以反复调用。
相比于无优化的版本,开启优化后对寄存器的使用变得非常灵活,不再是死板的仅作为计算时的存储工具,内存操作减少了 \(\frac{2}{3}\) 。
那为什么实际上汇编代码量 O2 后成倍数减少,但运行时间没有成倍数减少呢。这就涉及内存延迟的概念。
内存读取有一个延迟时间,相比于计算耗时,这个延时要大得多,但这个延迟只会在最开始被等待一次,因为读取过程中 CPU 可以在等待延迟的同时发出读取指令,同时读取。就像烧水一样,烧一壶的同时灌上另一壶,可以有效节省时间。被读取过一次的内存,会被放入高速缓存,读取变得更快。
这是 O2 优化的第一个部分。
对寻址的优化
寻址主要指将数据从内存或者缓存加载的寄存器的过程。我们再这里忽略计算地址需要的时间。
还是两张图说明。
可以看到,在做前缀和的过程中,开启优化后的代码,只有一次寻址和一次加操作,而我们没开优化的代码,操作的毒瘤程度就难以形容了。
平常有些代码看起来很傻,实际上开了 O2 之后效率更优秀,就是采用的对编译器更友好的写法,当然,我们也没必要去太注意这些。
从汇编角度比较函数调用和宏定义
开了 O2 之后,这俩的区别不大,不开 O2,由于在 CPU 流水线中 ret 指令会带来严重中断,所以小函数还是写宏定义比较好。
注意,在 C++11 以后,inline 关键字已经被启用,开启 O2 优化后会自动内联,减少函数调用带来的开支。
可以通过和 g++ 同时安装的 gprof
对程序进行性能分析确定复杂度瓶颈。
引用一些宏定义的资料。
long long 与 int 的效率之争
通常来说,在 64bit 下,long long 和 int
的运算效率是没有差别的。但是由于高速缓存的问题,尤其是在某些数组大小为
\(10^5\) 左右的题目,如果
#define int long long,就很容易造成高速缓存不够用然后被迫放进内存减慢读写的情况。又或者是发生出现寄存器溢出,两个
int 类型可以共用一个寄存器但是一个 long long
不行。编译器不敢假定你的 long long 类型存储的数据是 int
范围的