平衡树
既然标题敢写平衡树,那就需要来谈谈平衡树本身,而不仅仅是实现它的方法。
平衡树本身
平衡树是一颗二叉搜索树,每个节点权值 大于左子树所有节点,小于右子树所有节点。
和线段树相比,它是一种动态结构,适合维护结构动态变化的信息,比如需要支持插入和删除以及翻转的序列,也可以用来维护一棵树(LCT)
和块状链表相比,它只能处理能够快速合并的信息,但是复杂度有所降低。
实现
Splay
已经很熟悉的方式,不再多说,不过可以多嘴提一句势能分析。
势能分析原理
定义势能函数 \(F(S)\) 表示状态 \(S\) 的势能,定义操作代价 \(p_i=c_i+F(S')-F(S)\) ,其中 \(c_i\) 表示操作时间。
求解 \(\sum p_i=\sum c_i +
F(S_m)-F(S_0)\)
移项得到 \(\sum c_i=\sum
p_i+F(S_0)-F(S_m)\)
一般来说,\(c_i\)
会比较奇怪,但是通过 \(F\)
函数的变化值可以去抵消掉这个奇怪的值得到优雅的 \(p_i\) ,然后一般来说最后的复杂度和 \(\sum p_i,F(S)\) 同阶
分析 Splay
的复杂度和单旋的复杂度
定义势能函数,定义单点势能 \(w(u)=\log_2(size_u)\) , \(F(S)=\sum\limits_{u\in S} w(u)=O(n\log
n)\) 。
旋转点为 \(x\) ,父亲为 \(f\) ,祖父为 \(g\) 。
左旋代价
注意到 \(size_{x'}=size_{fa}\) 。
\(1+w(x')+w(fa')-w(x)-w(fa)\le
1+w(fa)-w(x)\le 1+w(x')-w(x)\)
双左旋代价
\(1+w(x')+w(f')+w(g')-w(x)-w(f)-w(g)\le
1+w(f')+w(g')-w(x)-w(f)\)
\(w(f)\ge w(x),w(f')\le
w(x')\)
\(w(x')-w(x)\ge
w(f')-w(f)\)
\(1+w(f')+w(g')-w(x)-w(f) \le 1+
w(x')+w(g')-2w(x)\)
若 \(w(x')-w(x) \ge 1\)
则 $ 1+ w(x')+w(g')-2w(x)(w(x')-w(x))$
否则因为先旋的 \(f\) ,所以 \(g'\) 下的点不包括 \(x\) 中的点,所以有 \(size_x\ge size_{g'}\) ,因此 \(w(x')-w(g') \ge1\)
得到 \(1+ w(x')+w(g')-2w(x)\le
2(w(x')-w(x))\)
综上 \(1+w(x')+w(f')+w(g')-w(x)-w(f)-w(g)\le
3(w(x')-w(x))\)
左右旋代价
\(1+w(x')+w(f')+w(g')\le
1+w(f')+w(g')-w(x)-w(f)\le
1+w(f')+w(g')-2w(x)\)
由于最终 \(f',g'\) 都是
\(x'\) 的儿子,所以 \(1+w(f')+w(g')-2w(x)\le2w(x')-2w(x)\)
所以 \(1+w(x')+w(f')+w(g')\le
2w(x')-2w(x)\)
双旋代价
注意到只会进行一次 zig 操作,所以可以忽视 zig 的那个
1,其余代价直接相加,得到 \(3\) ,因此
\(p_i=O(\log n)\) 。
观察到一次 Splay 操作的每个子操作可以弄成 \(3\) ,然后相加抵消掉得到 \(3+3w(x')-3w(x)\) ,是 \(O(n\log n)\) 级别,势能变化量为 \(O(n\log n)\) 级别,故时间为 \(O(n\log n)\) 级别。
单旋代价
单旋代价为左旋代价的和,每次 Splay 操作数为 \(O(n)\) ,故单旋的复杂度上界是 \(O(n^2)\)
总结
以上势能分析对 Splay 操作的要求是非常严格的,因此如果在查询中没有进行
Splay
操作,那么操作时间无法导致对应的势能变化,最后出现不正确的复杂度。
Treap
数据随机的情况下,一个堆(每个节点的权值均大于它全部后代的权值)的期望高度是
\(\log n\)
的,通过左右旋保证堆的性质,可以保证 Treap 的复杂度,左旋右旋和 Splay
完全相同。
FHQ_Treap
元素 val:需要维护的值。
权值 height:随机的,用于保持堆性质的值。
核心操作是 Merge 和 Split。
过程中需要时刻保证满足堆的性质
merge(u,v)
合并两个子树 u,v ,保证 u 中元素全部小于
v,返回根。
和线段树合并非常像。
1 2 3 4 5 6 7 8 9 10 11 int merge (int u,int v) if (!u||!v)return u^v; if (height[u]>height[v]){ son[u][1 ]=merge (son[u][1 ],v); push_up (u);return u; } else { son[v][0 ]=merge (u,son[v][0 ]); push_up (v);return v; } }
Split(u,x,y,k)
按照元素值小于等于 \(k\)
划分为两颗树,较小的那棵树树根为 \(x\) ,较大的那个树根为 \(y\) 。
细看这个函数其实相当妙。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void split (int u,int &x,int &y,int k) if (u==0 ){ x=y=0 ; return ; } if (val<=k){ x=u; split (son[u][1 ],son[u][1 ],y,k); } else { y=u; split (son[u][0 ],x,son[u][0 ],k) } push_up (u); }
其实也可以按照子树大小划分,用于文艺平衡树。
其它操作
get_l(element):按照小于 element
划分,然后返回较小那边的大小,重新 merge
get_element(rank):与 splay 没有差异。
insert(element):按照小于等于它划分,然后 merge 两遍。
erase(element):按照小于等于它划分,然后按小于它划分,然后把划分得到的两个儿子
Merge 起来再 merge,然后再
merge,这样是能够处理元素相同节点的 。
get_prev(element):按照小于它划分,用 get_element()
get_next(element):按照小于等于它划分,用 get_element()
合并的时候也可以按概率选择父亲,\(sz\) 较大的权重较大,期望复杂度可以证明是
\(O(n\log n)\) 的。
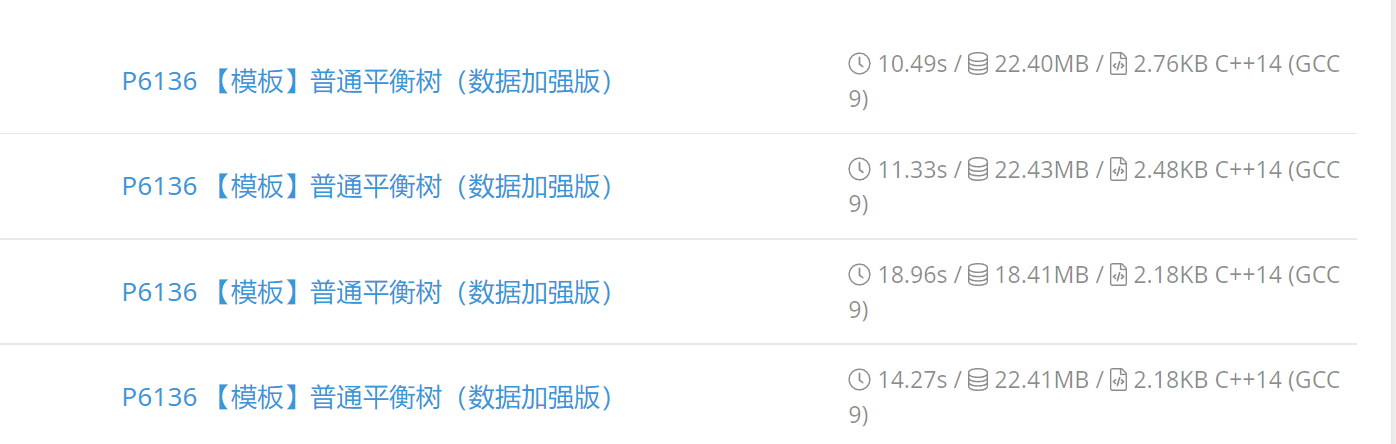
某些实验
采用佳老师的神奇插入删除方式:
image-20221013210116511
可以发现正常的插入方式需要 \(14S\) ,\(18S\)
是按子树大小概率合并,加上佳老师优化后变为 \(10S\) ,有一定改进。
如果直接实现 get_rank 系列函数可以更快,但是没什么必要了。
手写 get_rank 系列后耗时为 \(9S\) ,手写 get_rank
系列,采用正常插入方式,用时 \(12S\) 。
全实现的 Splay 需要 11S。
vector
一般来说,如果数据范围 \(\le 5\times
10^4\) ,或者时限比较宽松,可以用 vector
实现平衡树。
pb_ds
自带平衡树,一般用于操作比较简单的情况,如果需要打 Tag 之类的,重写
node_update 不如手写一颗。
可持久化平衡树
可持久化平衡树一般用于解决强制在线的历史版本问题,对于非强制在线问题,其实可以离线到树上实现一个支持撤销的平衡树。
对于强制在线问题,基本思路都是复制修改过的路径,复用没有修改过的路径。
可以发现其实任何一个版本创建之后就是静态的,所以可持久化数据结构的核心是:任何时刻访问先前的版本,都能得到正确的结果,任何修改不能影响到先前的版本。
Splay 实现
其它操作不变,Splay
时复制涉及 的所有点作为一个新版本。
但是,这玩意的复杂度有问题,Splay
的复杂度保证在于对操作进行势能分析,引入可持久化后,势能的变化量会变成
\(n^2\log n\) ,因此复杂度会退化。
由于实际应用中,很少存在只能用 Splay 的情况,因此没有必要深究 Splay
的可持久化。
FHQ-Treap 实现
听说这种实现有点问题,但是实际中并没有出现过问题,如果觉得不太行可以换下面那种奇怪的实现。
Split
由于操作都是从 Split 开始的,所以每次 Split
前都复制一个版本出来,具体的,像可持久化线段树一样把不变的儿子共用,改变的儿子复制。
Split
的路径上所有点的信息都被改变了,需要复制一遍得到新的,这样原先版本的所有节点不会有任何变化。
大致刻画以下 Split 中被修改的点,它呈一条链
Merge
Merge
过程中的复制不是必须的,原因是每个被修改的点都是被新建出来的点,这个证明可以考虑归纳,合并深度为
\(1\)
的节点时,两点显然都是被复制的,不影响原树,合并任何被复制的两个节点时,较小的那个的右儿子,较大的那个的左儿子要么不存在,要么是被复制的,因为在被复制的节点处,链一定会向下延申。
因此合并时可以不用新建节点。
神奇方法
佳老师有一个神奇写法,理论常数为 \(\frac{1}{2}\) ,具体的,插入和删除时先找到第一个
key 小于当前点 key
的点,然后这个点一定是被插入/删除点的儿子,然后把只对这个儿子做一遍
Split,并把树分到插入点的两个儿子上面去,这个思路同样可以用于一般
FHQ-Treap,运用在普通平衡树中,实际效率改进因子在 \(0.33\) 左右。
一般来说删除就正常搞,不然容易写错。
考试的时候如果不卡常就写正常写法,减少可能的错误。
一般来说,空间得开 50 倍。
注:效率改进因子,若效率改进因子为 \(x\) ,原时间 \(t\) ,则改进后时间为 \(\frac{t}{1+x}\) 。
Treap 实现
由于期望树高是 \(\log n\)
的,所以直接复制所有已经被修改的点的信息
某种奇怪的实现
类似 FHQ-Treap,但是 Merge
的时候按照子树大小作为权重,随机选一个做父亲,这样的复杂度是有保证的。
文艺平衡树
文艺平衡树是一类用于维护区间的平衡树,它和正常的平衡树类似,但是用树的结构来决定一个元素的大小,适合用来维护结构动态变化的序列。
一般用 Splay 和 FHQ-Treap 实现。
FHQ-Treap 实现时需要支持按 size 划分。
动态树
一般用 Splay 实现,复杂度 \(O(n\log
n)\) ,进行实链剖分,每条实链被一颗 Splay
维护,思想和文艺平衡树类似,用平衡树树的结构表明了原树节点中的的高度关系。
核心操作是 access 和 make_root。
access(x)
使得 \(x\)
到树根上的路径成为一条实链,断开 \(x\)
和它实儿子的连接,并让 \(x\) 成为该
Splay 的根。
make_root(x)
使得 \(x\) 成为树根,操作方式是先
accsess,然后翻转这条实链,使得 \(x\) 的深度最小。
由于虚儿子认父不认子,所以整个结构都没有问题。
实现
一般采用 Splay,FHQ-Treap 也没有问题。
但是不能用一般 Treap,因为一般 Treap
对树结构的要求决定了它无法进行旋转操作。
FHQ-Treap 的复杂度很难证明是 \(n\log
n\) ,但是可以保证上界为 \(O(n\log
n^2)\) ,Splay 的复杂度则为 \(O(n\log
n)\)
似乎有 \(O(n\log n)\) 的 FHQ-Treap
实现。