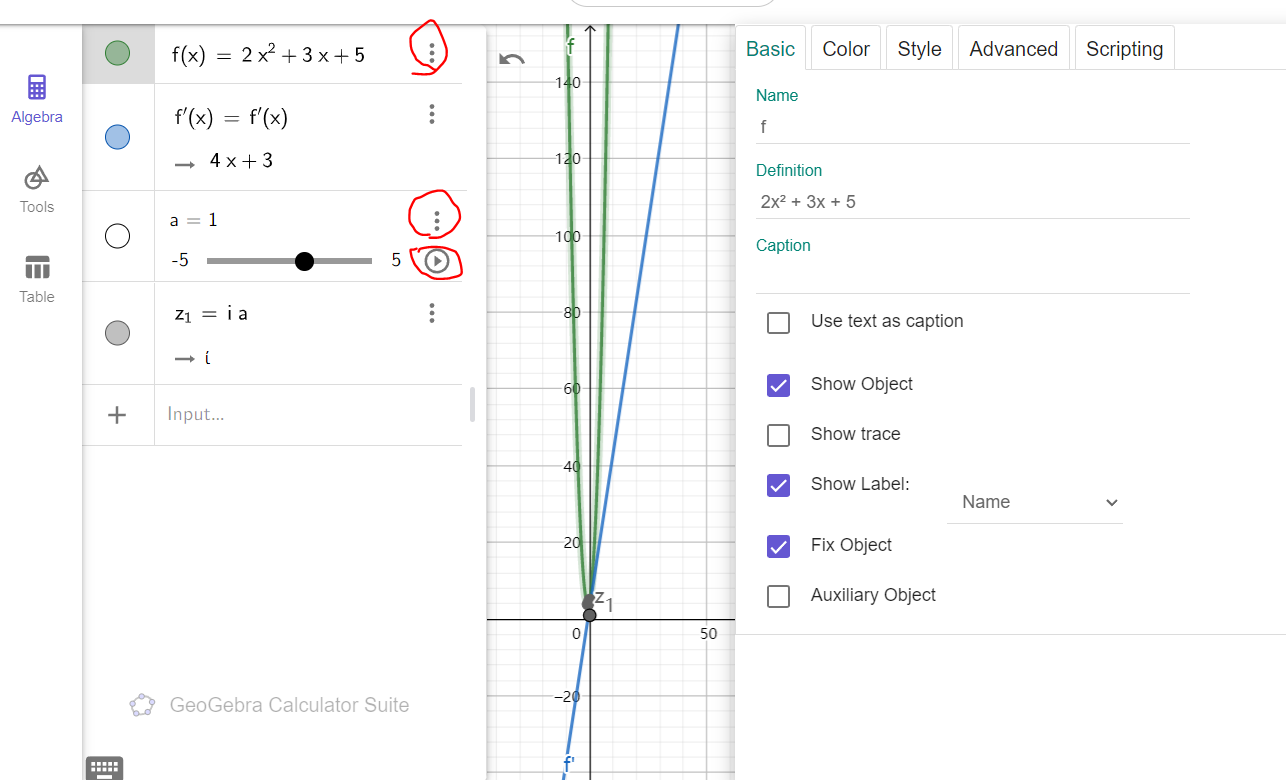
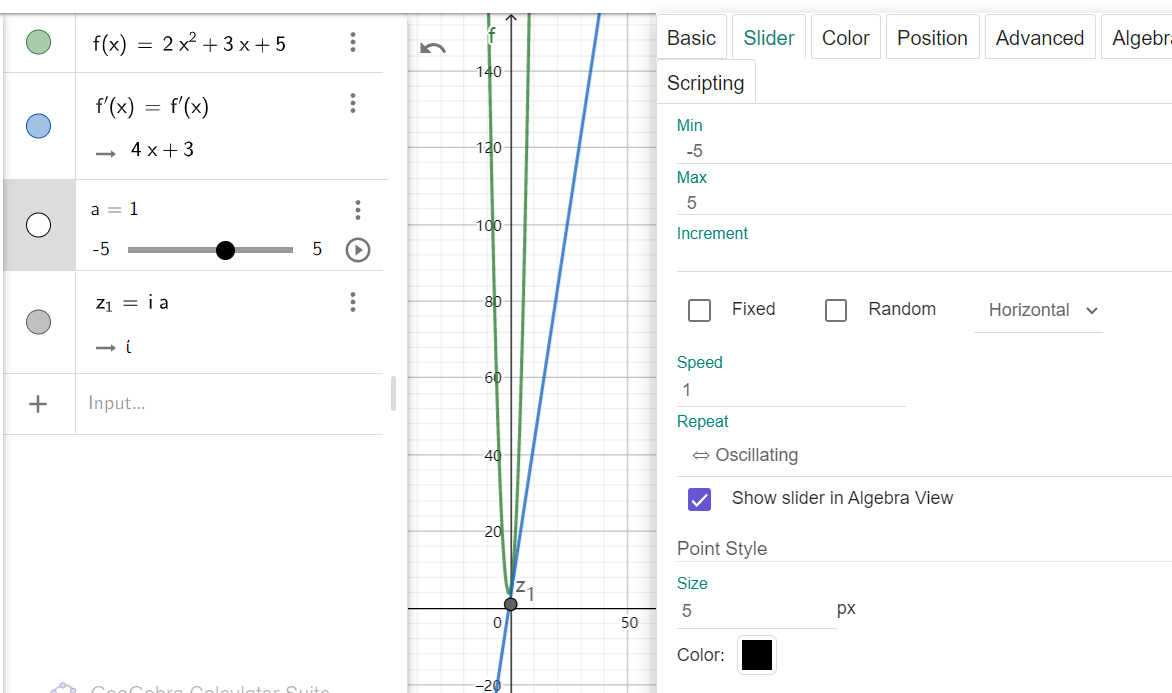
标准库
- STL
内的所有基于比较的容器,都需要定义一个满足严格弱序的比较符号
<,要求如下:
- 满足传递性:\(a<b,b<c\rightarrow
a<c\)
- 不能同时满足 \(a<b\) 且 \(b<a\)
- 如果
!(a<b)&&!(b<a) 那么
a=b
- 除开
array 之外的所有 STL
容器,定义时都会初始化,即初始化为空或者(全为 0,对于
bitset)。
- 基于比较的容器,需要定义友元类型的大小比较符号,因为实现的时候使用了右值做比较。
priority_queue
默认是大根堆,跑得很快,1 秒 \(3\times
10^6\)
如果需要实现可以删除的优先队列,必须保证每次删除时对应元素存在。
构造方式
priority_queue<type,container,cmp>,container
是实现 priority_queue 的容器,一般用
vector,cmp
是比较算子(因此它是一个类名)。
通过 greater<typename> 可以用重载的
> 构造出一个大于算子。
map
本质上是 set<pair<T1,T2>>,见
set。
set
insert
可以插入一段区间,支持数组,同类型的 set vector
容器。
开 O2,\(1\) 秒 \(1.5\times 10^6\) 次操作。
如果接下来的一段插入有序,开 O2,\(1\) 秒 \(4.5\times 10^6\)
次,所以尽量排序后再插入。
erase
开 O2,\(1\) 秒 \(1.5\times 10^6\) 次操作。
如果接下来的一段插入有序,开 O2,\(1\) 秒 \(4.5\times 10^6\) 次。
迭代器操作
开 O2,\(1\) 秒 \(10^7\)。
遍历
1
2
| for(auto v:st)
for(auto it=st.begin();it!=st.end();it++)
|
以上两种均为 \(O(n\log n)\)
开 O2,\(1\) 秒 \(10^7\) 次操作。
unordered_set
基础操作相比 set 快 \(2\) 倍。
有序操作和 set 效率差不多。
unoedered_map
本质上是 unordered_set<pair<T1,T2>>。
vector
比较理想的一个容器。
push_back()
一个 vector 做 push_back 需要
log 次 new,而 new
操作一般只能接受 \(2\times 10^7\)
次,所以尽量避免用太多 vector,如果能事先确定容器的
capacity,最好用 resize
iterator insert(iterator,val)
将 val 插入 iterator 位置,原
iterator 位置往后移动。
复杂度 \(O(n)\),但是跑得飞快。
iterator erase(iterator)
删除 iterator 位置的值,返回原容器(删除前)下一个位置的
iterator。
iterator
这东西的迭代器本质上是个指针,但是不能和指针做强转,所以
iterator 在被 erase 后会指向错误的数据,不同于
set 这一类基于 RBT 的容器。
内存过程
调用析构函数之前,vector
的内存不可能被释放,push_back 或者 resize
如果导致了内存改变,会开辟一块新的内存并将原有数据全部拷贝过去,保证内存地址的连续,同时原有迭代器全部失效。
vector 所有的 \(O(n)\)
操作都很快,如果题目性质决定了很可能 \(O(n^2)\) 卡不满,那么 vector
可以得到很高的分数。
拓展库
一个 C++ 拓展库,STL
升级版,C++11 特性。
gp_hash_table
Introduction
如名称,哈希表,比 unordered_map 快 3~4
倍,用法完全一样,你值得拥有。
效率 1S 能做 4e7 次基本操作
在 ext/pb_ds/assoc_container.hpp 中。
如果对非标准结构,例如类和 pair
,容器等,需要自己写哈希方法,哈希方式为一个类,重载了 ()
运算,该重载必须被声明为常函数,且参数必须为常值引用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include<ext/pb_ds/assoc_container.hpp>
__gnu_pbds:: gp_hash_table <int,int,hash_fun> mp;
struct node{
int a,b;
friend bool operator ==(const node &x,const node &y){
return x.a==y.a;
}
};
struct hash_fun{
int operator ()(const node &a) const{
return a.a;
}
};
__gnu_pbds:: gp_hash_table<node,int,hash_fun> mp;
mp.insert(make_pair(1,2));
mp[2]=3;
if(mp.find(2) != mp.end()){
printf("%d\n",mp.find(2)->second);
}
|
Tests:
这里只放关键部分,其余实现见代码
测试环境为 Windows10,CPU 型号为 Inter I7-9750H,内存 16GB,
2667Mhz
命中率对速度影响:
1
2
3
4
5
6
7
8
| gen_data(1e6,4e7,8,7);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
gen_data(1e6,4e7,8);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
|
插入和查询次数调整:
1
2
3
4
5
6
7
8
9
10
11
12
| gen_data(2e6,4e7,4,1);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
gen_data(5e6,4e7,4,1);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
gen_data(1e7,4e7,4,1);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
|
插入很多,查询很少。
1
2
3
4
| gen_data(2e7,4e6,50,1);
gp.clear();um.clear();
Test_Speed(gp);
Test_Speed(um);
|
其实插入操作比较慢是正常的,内存占用大了之后自然就慢了。
另外,手写哈希表探测法还有救,拉链法直接抬走(你写代码的时候考虑过
CPU cache 的感受吗?)。
插入较少且全部在查询前面 cc_hash_table 的效率优于
gp_hash_table。
Tree
虽然有这个东西,但是还是应该学习如何写平衡树。
效率还可以,开 O2
和以前手写差不多,估计现在手写的会快一些,不过问题不大。